
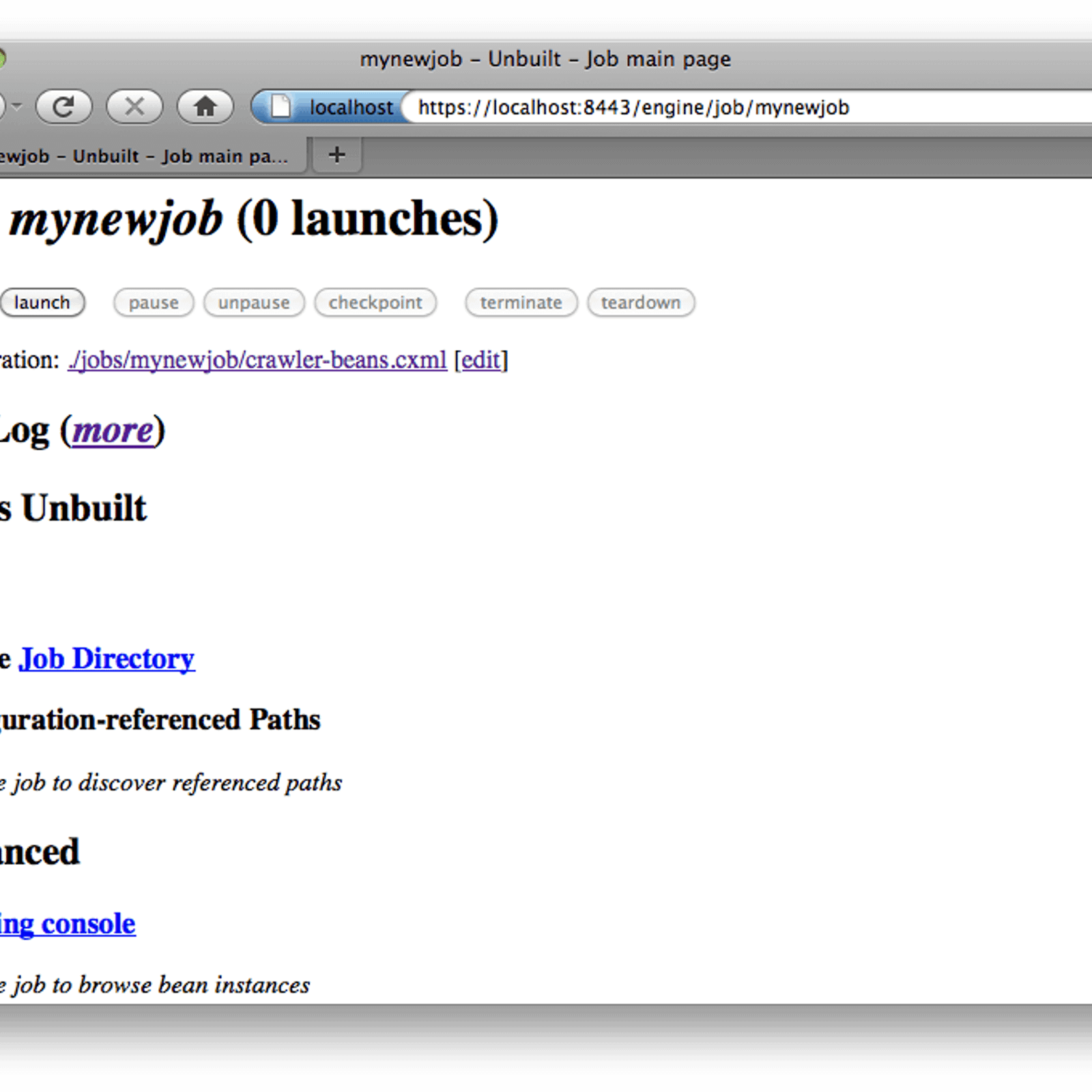
Heritrix is an open source web crawler designed for archiving web content. It is written in Java and runs in a Java servlet container, such as Tomcat or Jetty. It can be used to crawl both small and large websites, and can be configured to obey robots.txt and other web standards. Heritrix is used to capture and preserve digital content, such as web pages, images, videos, and other digital media, for archival and research purposes. It provides a range of features, such as distributed crawling, incremental crawling, and a web interface for monitoring and controlling the crawler. It also includes a powerful analytics system that can be used to measure the performance and effectiveness of the crawler. Heritrix can be used to create digital archives of websites, which can be used for research and historical preservation.
 Algolia
Algolia
 Mixnode
Mixnode
 Apache Nutch
Apache Nutch
 StormCrawler
StormCrawler
 Expertrec Search Engine
Expertrec Search Engine
 ACHE Crawler
ACHE Crawler
 Google Custom Search Engine
Google Custom Search Engine
Heritrix is mainly for tracking. I am not looking for